

实验室两位学生ACL 2020参会汇报
ACL 2020 (The 58th Annual Meeting of the Association for Computational Linguistic) 是自然语言处理领域最重要的盛会,于2020年7月5日至7月10日在线上举办。在中国计算机学会的国际学术会议推荐中,ACL为人工智能领域的A类会议。此次ACL会议的投稿数量为3088篇。ACL2020 接收了779篇论文,其中包含571篇长论文和208篇短论文,接收率为25.2%。

在此次会议中,实验室2018级博士生郭达雅和钟宛君分别以第一作者的一篇和两篇论文有幸被会议接收,并以线上口头报告的形式参会。发表的三篇论文受到国家自然科学基金和广东省大数据分析与处理重点实验室的支持。
郭达雅同学的论文“Evidence-Aware Inferential Text Generation with Vector Quantised Variational AutoEncoder” 主要关注推理文本生成,旨在理解日常事件并推断事件本身相关的常识性知识,如事件发生的原因,参与者的意图和情绪等。常识性推理的能力在多种NLP任务中具有重要的意义,如在文本生成中,能够理解事件之间的因果关系,从而生成合理的文本;在智能对话中,可以通过对话内容来推理出用户的意图和情感,有效地提高对话质量。在本文中,我们提出了一种面向证据的推理文本生成的方法,从语料库中自动寻找有用的背景知识,用来帮助模型的生成。给定一个事件,首先通过量子变分自编码器(VQ-VAE)得到具有语义信息的离散潜变量,然后从一个大规模的语料库中寻找包含事件和该事件上下文的证据。最后解码器利用具有该事件语义信息的潜变量选择语义相关的证据作为背景知识,从而指导推理文本的生成。该方法在文本推理的数据集Event2Mind和ATOMIC中取得最好的性能。
钟宛君同学的第一篇论文 “Reasoning over Semantic-Level Graph for Fact Checking” 提出了一个基于图的推理模型Dynamic REAsoning Machine (DREAM),该模型建模了声明与证据之间的语义相关性并对声明的真假性作出预测。DREAM推理模型主要分为三个步骤。第一步是基于XLNet预训练模型的词向量表示模块,首先通过抽取出来的语义结构,用拓扑排序算法对证据句子进行重排序,使得语义相关节点之间的相对距离更近,再用XLNet编码器学习图增强后的词向量表达。学习到的词向量被用于初始化图中的节点向量表示。然后,我们使用图卷积网络(Graph Convolutional Network)去对节点之间的信息进行传播和聚合,从而学习图中的结构化语义信息。最后,我们使用图注意力网络 (Graph Attention Network) 去匹配声明和证据中的语义结构信息,从而最初最终的预测。论文在句子级别的事实检测任务的代表性数据集FEVER上进行实验。在标签准确率和FEVER分数(同时考虑标签准确率和检索证据的准确性)上,均取得了最好的表现性能。
钟宛君同学的第二篇论文“LogicalFactChecker: Leveraging Logical Operations for Fact Checking with Graph Module Network” 提出了一个在神经网络中建模逻辑操作的方法: Logical Fact Checker。方法主要分为四个步骤。首先,给定一个表格和声明,我们使用语义解析器(Semantic Parser)去生成一个可在表格上执行的程序,该程序由预先定义好的逻辑操作组成。接下来,我们为了表示声明,表格,以及生成程序之间的语义结构化关系,我们构建了一个图。根据构建的图,我们定义了基于图的注意机制矩阵(attention mask metric)。矩阵被用于BERT编码器的自注意机制中(self-attention mechanism),以学习图增强的词汇表示(Contextual Representation)。之后,我们通过图模块化网络(Graph Module Network)去学习基于逻辑操作的语义组合性。论文在基于表格的事实检测的代表性数据集TABFACT上进行实验。可以看出,我们的方法超越了基于文本匹配的模型Table-BERT, 也超过了基于语义解析的模型LPA,并取得了最好的性能。
参会感想:
会议的第一天和第二天主要是Tutorial,介绍了目前最受关注的一些研究方向和具体方法。如开放领域的文本问答,机器学习模型的可解释性,基于常识推理的自然语言处理技术等。线上会议比较线下会议的优势在于可以听讲座的重播。我们听了最近比较关注的机器学习的可解释性,常识推理,还有开放领域的问答系统。机器学习的可解释性讲座讲述了如何使用探针法,设计合理的评测任务和可视化方法来解释机器学习做出的判别和特征在模型中的重要性。
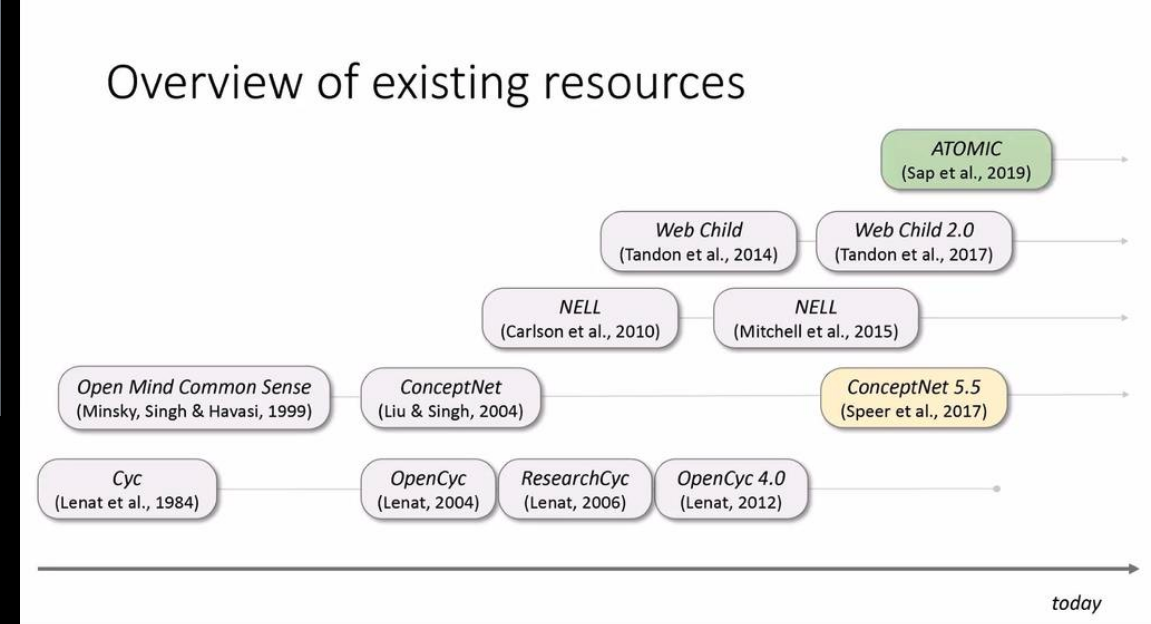
而基于常识推理的机器学习讲座讲述了现存的常识知识库,以及一些比较出名的在机器学习中融合常识知识的方法还有相关的评测数据集。
开放领域的问答系统讲座介绍了现存的开放领域问答数据集,以及基于检索和问答的相关方法,基于预训练模型的开放领域问答系统,以及Zero-shot设置下的问答系统。
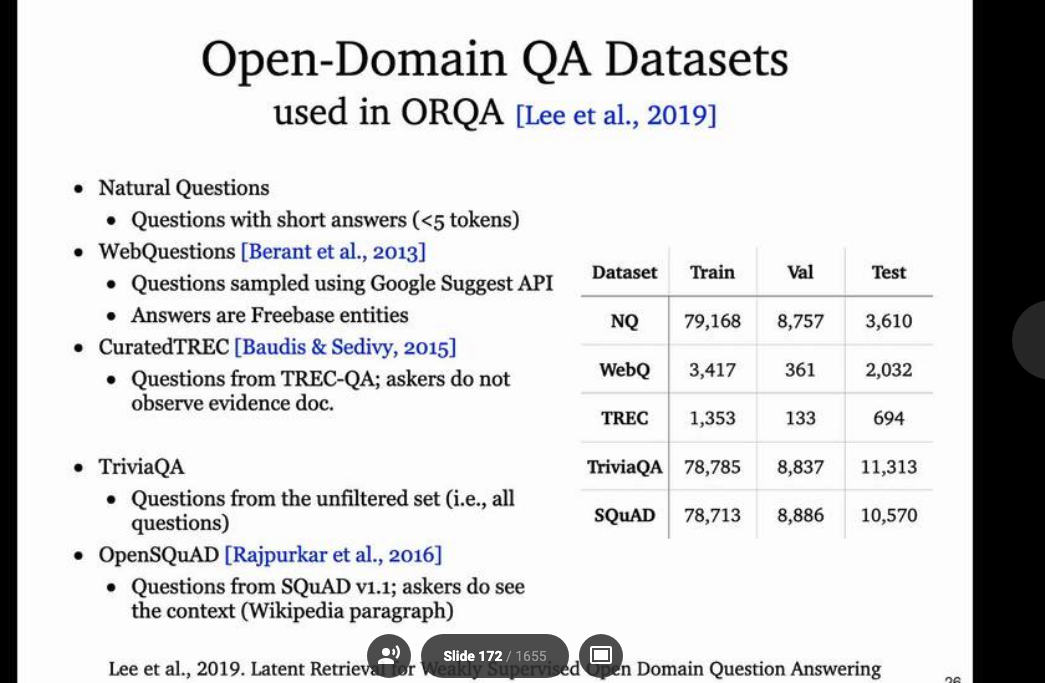
后面的几天主要是论文的QA以及观看感兴趣的论文的口头报告,还有参加一些线上的社交活动。线上会议也提供了一个方便和可交流的平台来分享自己的工作,以及学习其它研究人员的工作,从中学习领域最新的进展,开阔研究思路。
来源:钟宛君、郭达雅