

实验室学生EMNLP 2020参会汇报
EMNLP 2020(The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP2020)) 是自然语言处理领域最重要的盛会,EMNLP是由国际语言学会(ACL)下属的 SIGDAT 小组主办的自然语言处理领域的顶级国际会议,今年由于疫情转为线上举办。EMNLP 2020 录取结果为:接受论文754篇,接收为Findings论文520篇,被拒论文1840篇,总体接收率为24%。

在此次会议中,实验室2018级博士生钟宛君以第一作者的论文有幸被会议接收,并以线上口头报告的形式参会。
Deepfake检测是旨在自动识别机器生成文本的任务。随着自然语言生成模型的快速发展,这个任务也变得愈发重要。现存的deepfake检测方法基本上用粗粒度的表示去编码文章,无法建模文章中蕴含的事实结构。根据我们的数据分析,文章中的事实结构是区分人写的文章和机器生成文章的重要判别性因素,因此我们提出了一个基于图的模型去建模文章中的事实结构。给定一篇文章,我们用一个实体图去表示它的事实结构,然后使用图神经网络去计算句子的表示。进一步,我们建模了句子之间的连续性,把句子表示组合成文章级别的表示去做最终的预测整个算法的框架如图1所示。我们的方法在两个公开数据集上都显著超越了基准模型RoBERTa。并且样例分析更指出了,我们的模型可以区分出人写的文章和机器生成的文章在事实结构上的差异性。图2给出了一个样例分析。
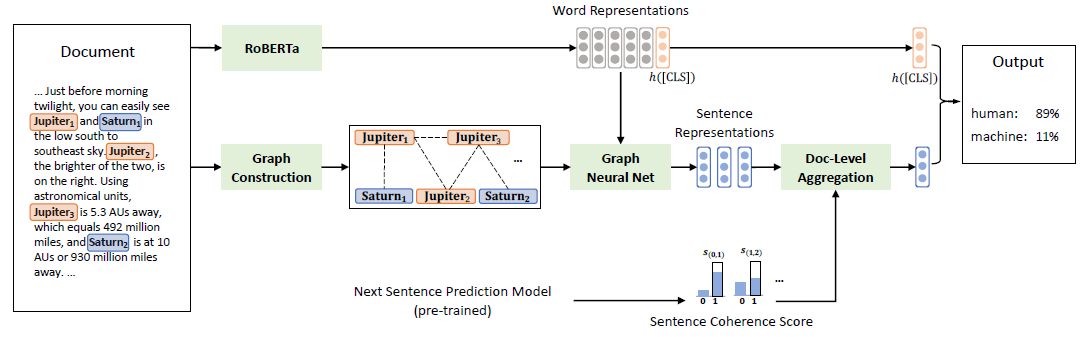
图1. 算法框架:给定一篇文章,我们使用RoBERTa去计算文章中词的上下文表示,并且用图去表示文章的事实结构。然后,我们用图神经网络去计算句子的表示。最后,我们建模了连续句子之间的关联性,把句子表示组合成文档表示,并做最终的预测。
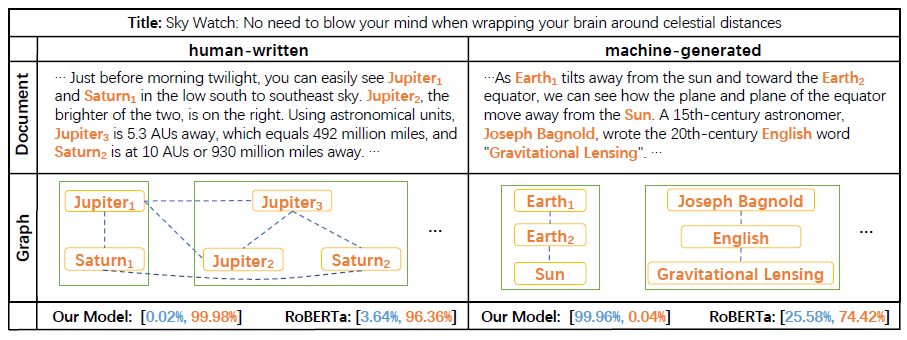
图2. 方法样例分析:连续的单词(橙色)代表抽取出来的一个实体。每个绿色方框代表对应于一个句子的子图。蓝色虚线代表语义相关的实体对之间的边。橙色和蓝色的数字分别代表判别为人写的文章和机器生成文章的概率。
来源:钟宛君